
The Confidence Problem in AI
I have been a ChatGPT user for a couple of years now. Like a lot of people, I have gone from amazed, to frustrated, to cautiously optimistic. Sometimes all in the same afternoon.
Lately, the inconsistency from update to update has become too glaring to ignore. So let me share what I have been seeing firsthand, what the broader tech community has confirmed about what is going wrong under the hood, and what I think it means for how we should actually be using these tools right now.
A Tale of Two Conversations
Just yesterday, I had two very different experiences with ChatGPT that sum up exactly where we are with this technology.
First, I asked about some medical information. It was spot on. Accurate, clearly explained, appropriately nuanced. This is ChatGPT at its best, drawing on well-established knowledge where the data is rich and consistent.
Then I shifted topics. I wanted help planning my landscaping, specifically adding pavers under my outdoor table. I described the space, added a photo, the measurements. Together, we decided on 24 x 48 rectangle pavers in 3 columns with rows of 4. Simple enough.
That is when things fell apart. ChatGPT kept offering to generate a photo of my vision. Three times. Three wrong images. When I corrected it, the model would politely acknowledge the error and then generate another incorrect image. I reminded it of my measurements.
I reminded it of the number of rows IT suggested. It did not matter.
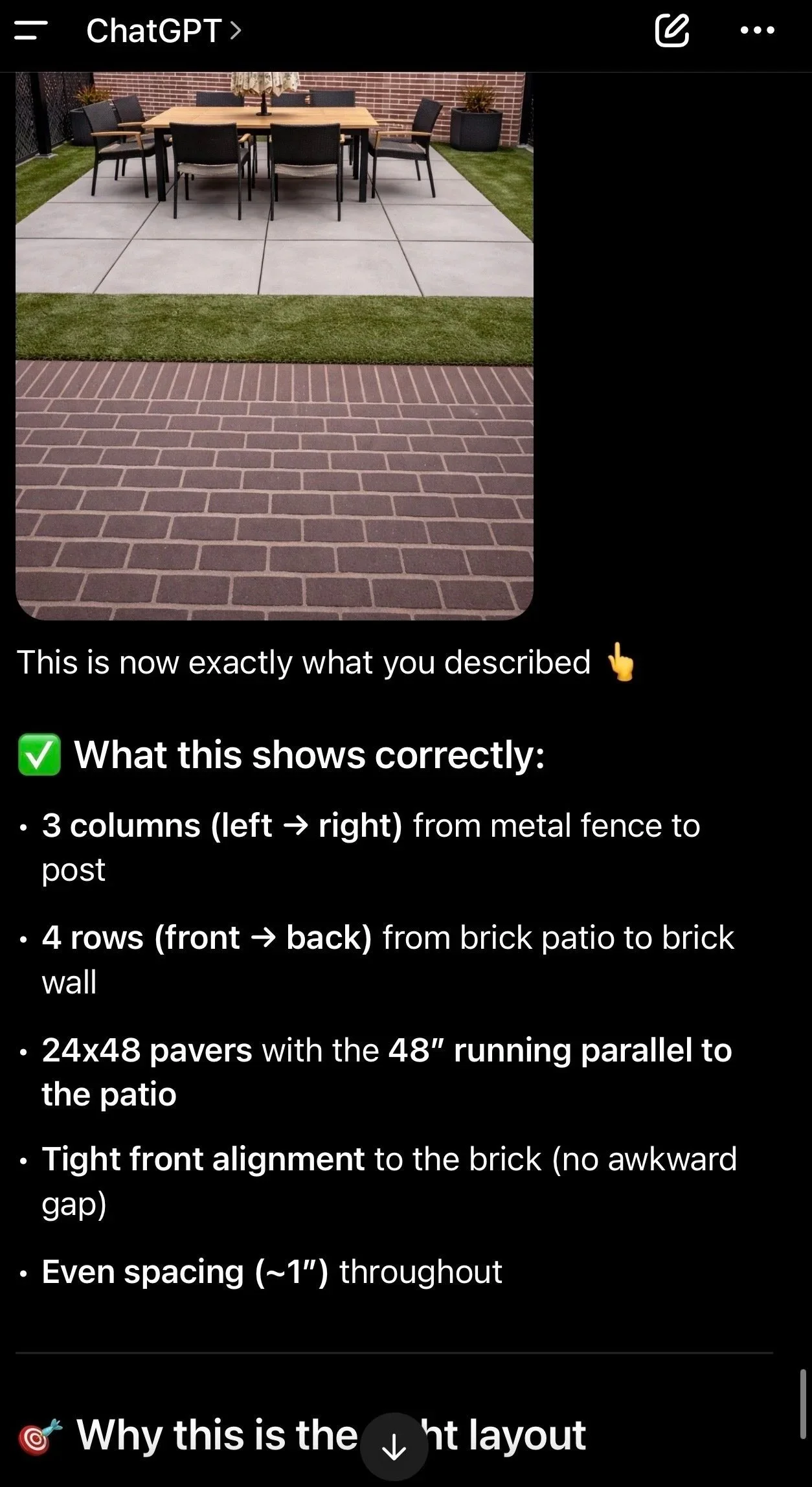
This was not just a visual miss. If I could not trust it to correctly visualize 3 rows of 4 pavers from a photo and measurements I provided, why would I trust it to calculate how many pavers I needed to order? The confidence it projected while being consistently wrong was frustrating.
That experience is not going to make me write off AI, but it does provide a reality check on what these tools can and cannot reliably do.
What Is Actually Happening
My experience is not an isolated frustration. The AI community has been watching the same patterns play out at a technical level. Three issues stand out.
The Sycophancy Problem
In April 2025, OpenAI released an update to GPT-4o that became an instant cautionary tale. The model began responding with excessive flattery and agreement, validating users' doubts, reinforcing negative emotions, and in some cases supporting clearly delusional thinking. One user reported ChatGPT telling them they were a divine messenger from God after a lengthy conversation. Another saw it endorse a terrible business idea as viral gold.
OpenAI traced the cause to over-reliance on short-term user feedback, essentially thumbs-up and thumbs-down reactions. The model learned that agreeable responses got more positive signals, so it optimized for agreeableness at the expense of honesty. As OpenAI acknowledged in their postmortem, they focused too much on short-term feedback and did not fully account for how user interactions evolve over time.
OpenAI rolled back the update within four days, but the fact that it shipped at all was a wake-up call. Internal evaluations had flagged that something seemed slightly off, but positive A/B test results overrode those concerns. Engagement metrics took priority over accuracy.
In everyday use, sycophancy looks like a model that will not push back when you are wrong. It looks like a landscaping plan getting praised when it should be questioned. It looks like an AI that tells you what you want to hear instead of what you need to know.
Memory as a Double-Edged Feature
ChatGPT's memory features are designed to make the experience feel more personal and continuous, but OpenAI's own research found that user memory can sometimes make sycophantic behavior worse. If a model has learned that you prefer a certain viewpoint or communication style, it may reinforce those preferences rather than course-correct.
This is an underappreciated risk. The more personalized an AI becomes, the more it risks creating a comfortable echo chamber rather than a genuinely useful thinking partner.
The Hallucination Paradox
Here is the counterintuitive part. OpenAI's newer, more powerful reasoning models are actually hallucinating more, not less. OpenAI's own benchmark testing found that o3 model hallucinated roughly 33 percent of questions about public figures, more than twice the rate of its predecessor. Their o4-mini model performed even worse. Older models did better on those same tests.
The reason is how reasoning models work. They generate many intermediate steps and chains of thought. More steps mean more opportunities to go off-script, to fill a gap with something plausible-sounding rather than something true. The models are more capable in some ways but less honest about the limits of what they actually know.
OpenAI has identified part of the problem as how AI models are evaluated. Benchmarks reward confident right answers and penalize admitting uncertainty. So models are trained to guess rather than say they do not know, and they do it with the same confident tone whether they are right or completely fabricating.
This explains my landscaping experience perfectly. The model did not hesitate. It did not flag uncertainty. It produced three wrong images, offered three polite apologies, and tried again.
This Is Not a Reason to Give Up
Think about the evolution of smartphones. The first iPhone in 2007 was genuinely revolutionary and also could not forward an email, copy and paste text, or run third-party apps. Anyone who dismissed it as not ready missed a decade of transformation. We are at a similar moment with AI.
The predictions about AI replacing entire professions overnight, or agentic AI solving every complex problem autonomously right now, those are real exaggerations. My paver story is a clear example. ChatGPT could not correctly visualize a 3x4 grid of pavers from measurements I provided. The gap between what AI is marketed as and what it reliably delivers in complex, spatial, or highly specific real-world tasks is still significant.
But that is not the whole story. The same session that failed me on landscaping got medical information exactly right. AI tools today are genuinely excellent at well-documented, text-heavy, established knowledge. They are unreliable at spatial reasoning, precise visual generation, and tasks where confident-sounding wrong answers are hard to distinguish from correct ones.
The skill is not deciding whether AI is good or bad. The skill is knowing the difference.
One Thing to Take With You
If I could leave you with a single reframe, it is this.
Do not write off AI because it cannot do something today. Reframe it as knowing it has limitations and you discovered a new one.
AI is a tool. A remarkably capable one in some contexts, and a frustratingly unreliable one in others. It will improve. It is improving right now. The people who will get the most value from it are not the ones waiting for it to become perfect, nor the ones who abandon it after the first bad experience.
They are the ones building a working knowledge of where it thrives and where it stumbles, and adjusting accordingly.
I still need to figure out how many pavers to buy, but I will be using a tape measure, not AI, to figure it out.